Humans No Match for Go Bot Overlords?
AI Machine LearningSince my time away from blogging, I’ve found a new distraction addiction to keep my overactive mind busy. It’s called Go, an ancient strategy game that’s really big in the Asian world but catching on here. Its a fun game and I routinely get beat online by 6 year old children from all over the world.
So, what does Go have in common with neural nets and AI? Quite a lot actually because programmers are working frantically to build a Go program that can beat humans. So far they haven’t had success because school children routinely beat these programs but that could be changing, all through the use of the Monte Carlo< method:
Called the Monte Carlo method, it has driven computer programs to defeat ranking human players six times in the last year. That’s a far cry from chess, the previous benchmark of human cognitive prowess, in which Deep Blue played Garry Kasparov to a panicked defeat in 1997, and Deep Fritz trounced Vladimir Kramnik in 2006. To continue the golf analogy, computer Go programs beat the equivalents of Chris Couch rather than Tiger Woods, and had a multi-stroke handicap. But even six victories was inconceivable not too long ago, and programmers say it won’t be long before computer domination is complete.
But the programmers admit that they’re merely throwing brute computational force behind this algorithm and they’re missing the nuances of intelligence that allow humans to continue to beat these programs.
“People hoped that if we had a strong Go program, it would teach us how our minds work. But that’s not the case,” said Bob Hearn, a Dartmouth College artificial intelligence programmer. “We just threw brute force at a program we thought required intellect.” [By Brandon Keim]
Well I think they’re still a way off before that can happen but in the meantime I highly recommend this game to anyone. Especially those with artificial and human intelligence. =)
Update 2020
This is an old post where I wrote how computer will never solve playing Go. In case you’ve been living under a rock, Google’s Deepmind made AI history. Google developed AlphaGo, a deep learning program and the top Go player in the world,Lee Sedol.
Lee Sedol is an 18 time world champion and AlphaGo is beating the pants off him. AlphaGo just won it’s 3rd game (out of 5) and it’s looking like it will sweep all 5 games.
I’m quite astounded and amazed. Just two years ago I told Ingo that I thought it wouldn’t happen for decades, but he had more faith in AI research and development than I did. In fact he reminded me of it! :)
Betting that #AI cannot do "X" has been a losing bet for X=#Chess, Go, #SelfDriving cars, probably any X @ingomierswa @neuralmarket
— KDnuggets (@kdnuggets) January 28, 2016
Perhaps the best comment about this is what Greg Piatetsky of KD Nugget opined. Betting against AI is a losing bet, it’s just a matter of time before it can solve any problem.
After AlphaGo won 4 to 1 against Lee Sedol, the world is a buzz with excitement and fear of AI. Although we’re still a long way from the “rise of the machines,” but we are getting closer.
AlphaGo does use simulations and traditional search algorithms to help it decide on some moves, but its real breakthrough is its ability to overcome Polanyi’s Paradox. It did this by figuring out winning strategies for itself, both by example and from experience. The examples came from huge libraries of Go matches between top players amassed over the game’s 2,500-year history. To understand the strategies that led to victory in these games, the system made use of an approach known as deep learning, which has demonstrated remarkable abilities to tease out patterns and understand what’s important in large pools of information. via NY Times
Polanyi’s Paradox states that we humans know more than we can tell, which is really our tacit knowledge. For the longest time AI couldn’t do that, couldn’t know more than what it can tell. It just relied on hard rules and brute force computations. AlphaGo changed all that.
For the first time ever, AI is breaking through the paradox, which is cool and scary at the same time. Once AI can figure out how to reprogram itself or make better machines than we can design, we’ll be in trouble.
AutoML Zero
I wanted to briefly touch on my last line above about “Once AI can figure out how to reprogram itself.” This is happening already with Google’s AutoML Zero. While this is in a slightly different use case space, it shows how the AI can assembled the right ‘chunks’ of code to optimize an outcome.
DeepMind Documentary
I highly recommend watching how DeepMind created AlphaGo and how it played against Go champions.
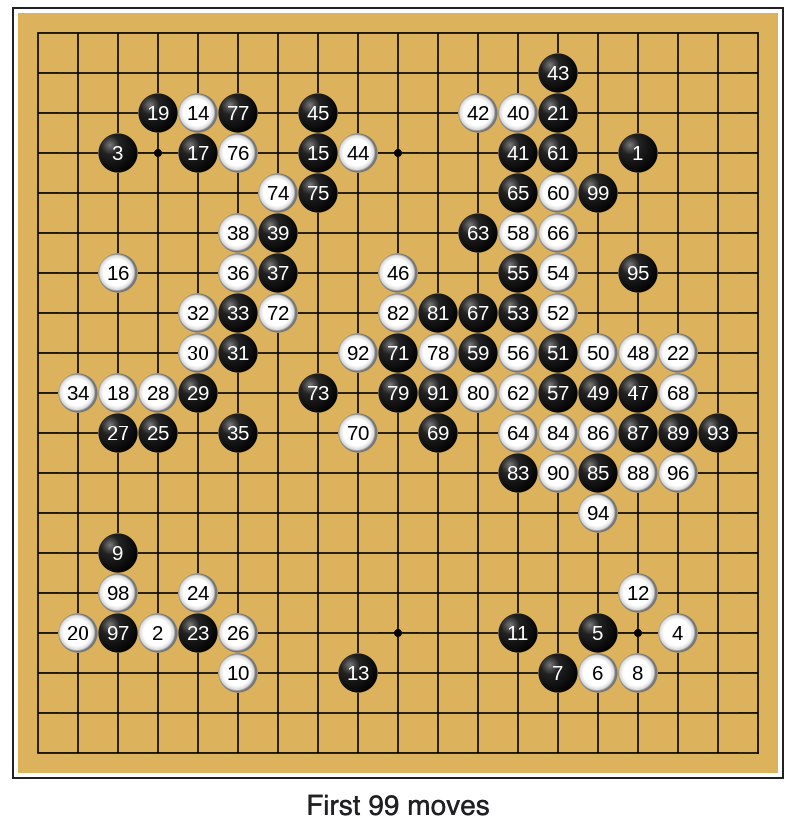
There’s some interesting commentary around the 2nd game against Lee Sedol where AlphaGo played a very unconventional move. It’s been dubbed Move 37 because, it was move #37, but what AlphaGo did was want no professional player would ever do. Play the 5th line made everyone question if AlphaGo was mad or if it was some sort of creative genius.
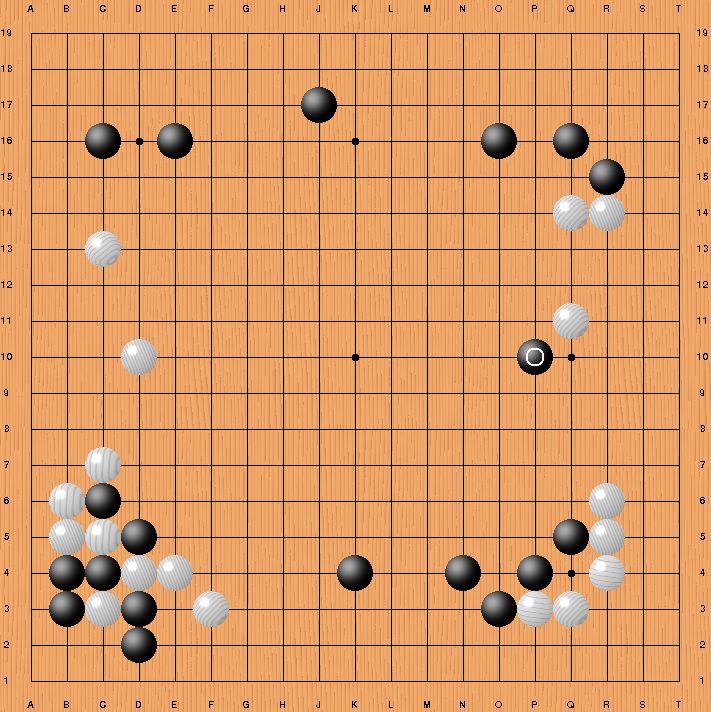
Lee Sedol responded with Move 78 in the 4th game which threw Alpha Go for a loop. It’s been dubbed ‘God’s Touch’ because it was a move that AlphaGo calculate was a 1 in 10,000 probability and never thought he would play it, but that stone created a wedge in Black’s territory and AlphaGo couldn’t recover.