If you want to execute any Python in RapidMiner, you have to use the Execute Python operator. This operator makes things so simple that people use the hell out o fit. However, it wasn’t so simple in the “old days.” It could still be done but it required more effort, and that’s what I did with the Julia Language. I mashed up the Julia Language with RapidMiner with only a few extra steps.
The way we mashed up other programs and languages in the old days was to use the Execute Program operator. That operator let’s you execute arbitrary programs in RapidMiner within the process. Want to kick of some Java at run time? You could do it. Want to use Python? You could do that (and I did) too!
The best part? You can still use this operator today and that’s what I did with Julia. Mind you, this is tutorial is a simple Proof of Concept, I didn’t do anything fancy, but it works.
What I did was take some a RapidMiner sample data set (Golf) and pass it to a Julia script that writes it out as a CSV file. I save the CSV file to a working directory defined by the Julia script.
Tutorial Processes
A few prerequisites, you’ll need RapidMiner and Julia installed. Make sure your Julia path is correct in your environment variables. I had some trouble in Windows with this but it worked fine after I fixed it.
Below you’ll find the XML for the Rapidminer process and the simple Julia script. I named the script read.jl and called from my Dropbox, you’ll need to repath this on your computer.
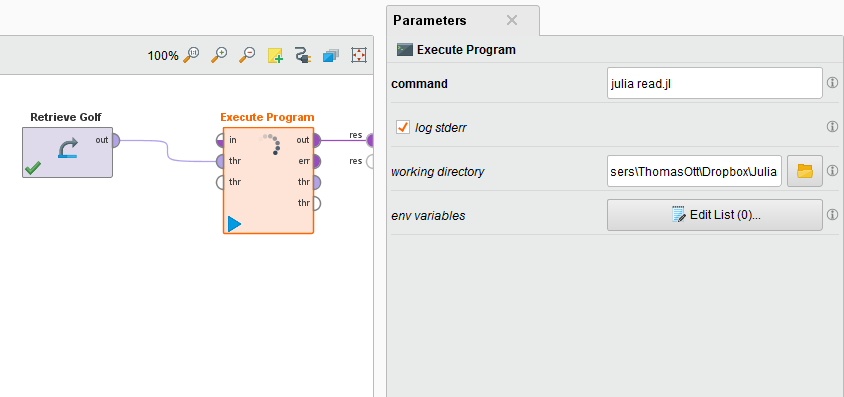
The RapidMiner Process
<?xml version="1.0" encoding="UTF-8"?><process version="7.4.000">
<context>
<input/>
<output/>
<macros/>
</context>
<operator activated="true" class="process" compatibility="7.4.000" expanded="true" name="Process">
<process expanded="true">
<operator activated="true" class="retrieve" compatibility="7.4.000" expanded="true" height="68" name="Retrieve Golf" width="90" x="45" y="34">
<parameter key="repository_entry" value="//Samples/data/Golf"/>
</operator>
<operator activated="true" class="write_csv" compatibility="7.4.000" expanded="true" height="82" name="Write CSV" width="90" x="246" y="34">
<parameter key="csv_file" value="read"/>
<parameter key="column_separator" value=","/>
</operator>
<operator activated="true" class="productivity:execute_program" compatibility="7.4.000" expanded="true" height="103" name="Execute Program" width="90" x="447" y="34">
<parameter key="command" value="julia read.jl"/>
<parameter key="working_directory" value="C:\Users\ThomasOtt\Dropbox\Julia"/>
<list key="env_variables"/>
</operator>
<connect from_op="Retrieve Golf" from_port="output" to_op="Write CSV" to_port="input"/>
<connect from_op="Write CSV" from_port="file" to_op="Execute Program" to_port="in"/>
<connect from_op="Execute Program" from_port="out" to_port="result 1"/>
<portSpacing port="source_input 1" spacing="0"/>
<portSpacing port="sink_result 1" spacing="0"/>
<portSpacing port="sink_result 2" spacing="0"/>
</process>
</operator>
</process>
The Julia Language script
using DataFrames
df = readtable(STDIN)
writetable("output.csv", df, separator = ',', header = true)
Note: You’ll need to “Pkg.add(“Dataframes”)” to Julia first.
Of course the next steps is to write a more defined Julia script, pass the data back INTO RapidMiner, and then continue processing it downstream.